Probability
In this chapter, we will learn the basics of probability and statistical distributions in context of real world financial data. Then in later section, we will apply these concepts to get insights on our complete Finance data set.
- Probability Distributions
- Permutations and Combinations
- Probability Distributions Functions (PDFs)
- Calculating Probability Distributions on Finance data
Probability Distributions
how do you explain what a probability distribution in statistics is?
In simple terms, we use a single value to represent a group of data. This value is called the measure of central tendency and it describes what is typical or average in the data. Common measures of central tendency include the mean, median, and mode.
Probability and distributions aid in comprehending general patterns within data during statistical analysis.
For example, given a set of 100k different Mutual Funds or Stock prices estimated growth is, we want to have a general idea of about how each group of Mutual Fund or stock prices is performing in over all market conditions.
If you are wondering, why we even care of learning probability, statistics, algebra and calculus functions for the sake of Finance Analytics. It's because building AI, is all about using mathematics to find statistical association to rationally predict outcome of an event given a set of inputs, than casual reasoning.
As we progress, we will see, how learning statistical associations and using calculus for automation in small steps, lead to performing statistical tasks, automate predictive analytics, which are fast improved fact based statistical association rather than casual reasoning, and often outperforms human intuitive analytics.
ROI by Investment group data example
let's first review this sample example, we will use this data table example, in almost every section of this chapter below.
using DataFrames;
dfG = DataFrame(Group=["A","B","C","D"], ROI=[5.6,4.3,3.3,0.3]);
dfD = DataFrame(Group="A",Stocks="AAPL", Percent=35);
push!(dfD, ("A", "TSLA", 37));
push!(dfD, ("A", "OTH", 28));
push!(dfD, ("B", "GOOG", 36));
push!(dfD, ("B", "TSLA", 22));
push!(dfD, ("B", "NIKE", 42));
push!(dfD, ("C", "NIKE", 38));
push!(dfD, ("C", "MSFT", 42));
push!(dfD, ("C", "OTH", 20));
push!(dfD, ("D", "LOOSER_1", 25));
push!(dfD, ("D", "LOOSER_2", 25));
push!(dfD, ("D", "LOOSER_3", 25));
push!(dfD, ("D", "LOOSER_4", 25));
innerjoin(dfG, dfD, on = :Group)| Group | ROI | Stocks | Percent |
|---|---|---|---|
| A | 5.6 | AAPL | 35 |
| A | 5.6 | TSLA | 37 |
| A | 5.6 | OTH | 28 |
| B | 4.3 | GOOG | 36 |
| B | 4.3 | TSLA | 22 |
| B | 4.3 | NIKE | 42 |
| C | 3.3 | NIKE | 38 |
| C | 3.3 | MSFT | 42 |
| C | 3.3 | OTH | 20 |
| D | 0.3 | LOOSER_1 | 25 |
| D | 0.3 | LOOSER_2 | 25 |
| D | 0.3 | LOOSER_3 | 25 |
| D | 0.3 | LOOSER_4 | 25 |
ROI by Investment group data (transposed)
using DataFrames;
dfG = DataFrame(Stocks="AAPL",A=35,B=0,C=0,D=0);
push!(dfG, ("TSLA",37,22,0,0));
push!(dfG, ("OTH",28,0,20,0));
push!(dfG, ("GOOG",0,36,0,0));
push!(dfG, ("NIKE",0,42,38,0));
push!(dfG, ("MSFT",0,0,42,0));
push!(dfG, ("LOOSER_1",0,0,0,25));
push!(dfG, ("LOOSER_2",0,0,0,25));
push!(dfG, ("LOOSER_3",0,0,0,25));
push!(dfG, ("LOOSER_4",0,0,0,25));
transform!(dfG, [:A,:B,:C,:D] => (+) => :sum)| Stocks | A | B | C | D | sum |
|---|---|---|---|---|---|
| AAPL | 35 | 0 | 0 | 0 | 35 |
| TSLA | 37 | 22 | 0 | 0 | 59 |
| OTH | 28 | 0 | 20 | 0 | 48 |
| GOOG | 0 | 36 | 0 | 0 | 36 |
| NIKE | 0 | 42 | 38 | 0 | 80 |
| MSFT | 0 | 0 | 42 | 0 | 42 |
| LOOSER_1 | 0 | 0 | 0 | 25 | 25 |
| LOOSER_2 | 0 | 0 | 0 | 25 | 25 |
| LOOSER_3 | 0 | 0 | 0 | 25 | 25 |
| LOOSER_4 | 0 | 0 | 0 | 25 | 25 |
using UnicodePlots, DataFrames;
df = DataFrame(category=["A", "B", "C", "D"], ROI=[5.6,4.3,3.3,0.3]);
UnicodePlots.barplot(df.category, df.ROI,
xlabel = "ROI (%)", ylabel = "Category",
title="ROT by Investment group") ROT by Investment group
┌ ┐
A ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 5.6
Category B ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■ 4.3
C ┤■■■■■■■■■■■■■■■■■■■■■ 3.3
D ┤■■ 0.3
└ ┘
ROI (%) using DataFrames, CairoMakie; # hide
# prepare dummy data
dfG = DataFrame(Group=["A","B","C","D"], ROI=[5.6,4.3,3.3,0.3]); # hide
dfGT = DataFrame(Stocks="AAPL",A=35,B=0,C=0,D=0); # hide
push!(dfGT, ("TSLA",37,22,0,0)); # hide
push!(dfGT, ("OTH",28,0,20,0)); # hide
push!(dfGT, ("GOOG",0,36,0,0)); # hide
push!(dfGT, ("NIKE",0,42,38,0)); # hide
push!(dfGT, ("MSFT",0,0,42,0)); # hide
push!(dfGT, ("LOOSER_1",0,0,0,25)); # hide
push!(dfGT, ("LOOSER_2",0,0,0,25)); # hide
push!(dfGT, ("LOOSER_3",0,0,0,25)); # hide
push!(dfGT, ("LOOSER_4",0,0,0,25)); # hide
transform!(dfGT, [:A,:B,:C,:D] => (+) => :sum); # hide
dfD = DataFrame(Group="A",Stocks="AAPL", Percent=35); # hide
push!(dfD, ("A", "TSLA", 37)); # hide
push!(dfD, ("A", "OTH", 28)); # hide
push!(dfD, ("B", "GOOG", 36)); # hide
push!(dfD, ("B", "TSLA", 22)); # hide
push!(dfD, ("B", "NIKE", 42)); # hide
push!(dfD, ("C", "NIKE", 38)); # hide
push!(dfD, ("C", "MSFT", 42)); # hide
push!(dfD, ("C", "OTH", 20)); # hide
push!(dfD, ("D", "LOOSER_1", 25)); # hide
push!(dfD, ("D", "LOOSER_2", 25)); # hide
push!(dfD, ("D", "LOOSER_3", 25)); # hide
push!(dfD, ("D", "LOOSER_4", 25)); # hide
dfD = innerjoin(dfG, dfD, on = :Group); # hide
A = dfG[dfG.Group .== "A",:ROI]; # hide
B = dfG[dfG.Group .== "B",:ROI]; # hide
C = dfG[dfG.Group .== "C",:ROI]; # hide
D = dfG[dfG.Group .== "D",:ROI]; # hide
fig = Figure(backgroundcolor=:white, resolution=(600,500), fonts = (; regular = "CMU Serif"));
ax11 = Axis(fig[1,1], title="Group A",
titlecolor = :gray50,
titlegap = 10,
titlesize = 10,
xlabel="", xgridvisible=false, ygridvisible=false,
xticklabelsvisible=false, yticklabelsvisible=false,
);
ax12 = Axis(fig[1,2], title="Group B",
titlecolor = :gray50,
titlegap = 10,
titlesize = 10,
xlabel="", xgridvisible=false, ygridvisible=false,
xticklabelsvisible=false, yticklabelsvisible=false,
);
ax13 = Axis(fig[1,3], title="Group C",
titlecolor = :gray50,
titlegap = 10,
titlesize = 10,
xlabel="", xgridvisible=false, ygridvisible=false,
xticklabelsvisible=false, yticklabelsvisible=false,
);
ax14 = Axis(fig[1,4], title="Group D",
titlecolor = :gray50,
titlegap = 10,
titlesize = 10,
xlabel="", xgridvisible=false, ygridvisible=false,
xticklabelsvisible=false, yticklabelsvisible=false,
);
ax2 = Axis(fig[2,1:4], title="Stocks By Mutual Fund Group",
titlecolor = :gray50,
titlegap = 10,
titlesize = 10,
xlabel="", xgridvisible=false, ygridvisible=false,
xticklabelsvisible=false, yticklabelsvisible=false,
limits=(0,10,0,15));
ax3 = Axis(fig[3,1:4],
xlabel="", xgridvisible=false, ygridvisible=false,
xticklabelsvisible=false, yticklabelsvisible=false,
limits=(0,10,0,15));
colors = [:yellow, :orange, :red, :blue, :purple, :green]
pie!(ax11, dfGT[dfGT.A .> 0, [:Stocks, :A]].A, color=colors[1:length(dfGT[dfGT.A .> 0, [:Stocks, :A]].A)])
pie!(ax12, dfGT[dfGT.B .> 0, [:Stocks, :B]].B, color=colors[1:length(dfGT[dfGT.B .> 0, [:Stocks, :B]].B)])
pie!(ax13, dfGT[dfGT.C .> 0, [:Stocks, :C]].C, color=colors[1:length(dfGT[dfGT.C .> 0, [:Stocks, :C]].C)])
pie!(ax14, dfGT[dfGT.D .> 0, [:Stocks, :D]].D, color=colors[1:length(dfGT[dfGT.D .> 0, [:Stocks, :D]].D)])
scatter!(ax2,3,8, markersize=200)
scatter!(ax2,5,8, markersize=200)
scatter!(ax2,7,8, markersize=200)
scatter!(ax2,9,3, markersize=120)
text!(ax2,2.5,11, text = "A = $A%", color=:black, fontsize = 12)
label = dfGT[dfGT.Stocks .== "AAPL", [:Stocks, :A]].A
text!(ax2,2.5,8, text = "APPL $label", color=:black, fontsize = 12)
label = dfGT[dfGT.Stocks .== "OTH", [:Stocks, :A]].A
text!(ax2,2.5,6.4, text = "OTH $label", color=:black, fontsize = 12)
text!(ax2,3.6,7.5, text = L"TSLA", color=:black, fontsize = 12)
text!(ax2,4.5,11, text = "B = $B%", color=:black, fontsize = 12)
label = dfGT[dfGT.Stocks .== "GOOG", [:Stocks, :B]].B
text!(ax2,4.8,8, text = "GOOG $label", color=:black, fontsize = 12)
text!(ax2,7.0,11, text = "C = $C%", color=:black, fontsize = 12)
text!(ax2,5.9,7.5, text = L"NIKE", color=:black, fontsize = 12)
label = dfGT[dfGT.Stocks .== "MSFT", [:Stocks, :C]].C
text!(ax2,7.4,8.0, text = "MSFT $label", color=:black, fontsize = 12)
label = dfGT[dfGT.Stocks .== "OTH", [:Stocks, :C]].C
text!(ax2,7.4,6.4, text = "OTH $label", color=:black, fontsize = 12)
text!(ax2,8.8,5.8, text = "D = $D%", color=:black, fontsize = 12)
text!(ax2,8.4,1.8, text = "LOOSER", color=:black, fontsize = 12)
label = dfGT[dfGT.Stocks .== "LOOSER_1", [:Stocks, :D]].D
text!(ax2,8.7,3.3, text = "1 $label", color=:black, fontsize = 8)
label = dfGT[dfGT.Stocks .== "LOOSER_2", [:Stocks, :D]].D
text!(ax2,9.1,3.3, text = "2 $label", color=:black, fontsize = 8)
label = dfGT[dfGT.Stocks .== "LOOSER_2", [:Stocks, :D]].D
text!(ax2,8.7,0.4, text = "3 $label", color=:black, fontsize = 8)
label = dfGT[dfGT.Stocks .== "LOOSER_4", [:Stocks, :D]].D
text!(ax2,9.1,0.4, text = "4 $label", color=:blue, fontsize = 8)
text!(ax3,0.1,11, text = "A=[AAPL,TSLA,OTH]", color=:blue, fontsize = 10)
text!(ax3,0.1,9, text = "B=[GOOG,TSLA,NIKE]", color=:blue, fontsize = 10)
text!(ax3,0.1,7, text = "C=[NIKE,MSFT,OTH]", color=:blue, fontsize = 10)
text!(ax3,0.1,5, text = "D=[LOOSER 1,2,3,4]", color=:blue, fontsize = 10)
text!(ax3,3.1,11, text = L"A \cup B \cup C = [AAPL,TSLA,OTH,GOOG,NIKE]", color=:green, fontsize = 12)
text!(ax3,3.1,9, text = L"A \cap B = [TSLA]", color=:green, fontsize = 12)
text!(ax3,3.1,7, text = L"B \cap C = [NIKE]", color=:green, fontsize = 12)
text!(ax3,3.1,5, text = L"D = [1,2,3,4]", color=:green, fontsize = 12)
text!(ax3,3.1,3, text = L"(A \cup B \cup C) \complement = [1,2,3,4]", color=:green, fontsize = 12)
text!(ax3,8.1,10, text = L"P(A) = 0.35", color=:brown, fontsize = 12)
text!(ax3,8.1,8, text = L"P(T) = 0.37", color=:brown, fontsize = 12)
text!(ax3,8.1,6, text = L"P(O) = 0.28", color=:brown, fontsize = 12)
fig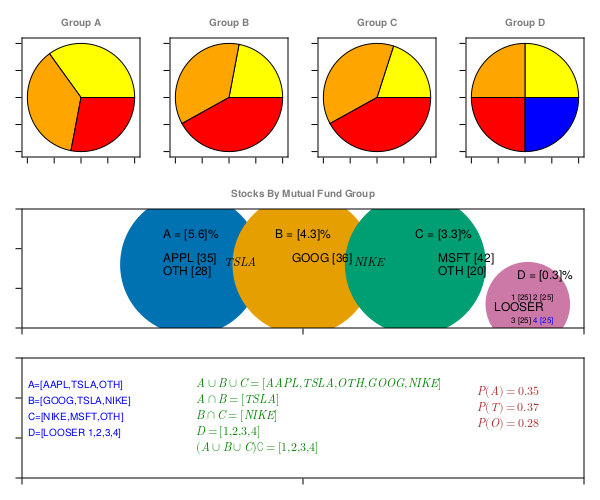
What is a Probability
A probability event is defined as set of outcomes of an experiment. In simpler words, Probability is likelihood of occurrence of an event.
As an example, What’s the probability of the getting a four on six face dice?
Calculating statistical probability mathematically helps us answer these type of questions.
\[ f = Number of favorable Outcomes \\ T = Total number of outcomes \\ P(X==4) = \frac{P(X==4)}{P(1)+P(2)+P(3)+P(4)+P(5)+P(6)} \\ P(X==4) = \frac{1}{1+1+1+1+1+1} \\ P(X==4) = \frac{1}{6}\]
Similarly, calculating mathematical probabilities may help us answer more complex questions like, given our Finance data, We may want to use Probability or likelihood of best possible return from given amount invested in certain investment group/category.
In ROI by Investment group data example, Category A has maximum ROI. Assuming, one Mutual Fund belongs to only one category, probability of getting maximum ROI on a given fund is 0.25.
\[ f = Number of favorable Outcomes \\ T = Total number of outcomes \\ P(X = maxROI) = \frac{f}{T} \\ P(X = maxROI) = \frac{P(C)}{P(A)+P(B)+P(C)+P(D)} \\ P(X = maxROI) = \frac{1}{1+1+1+1} \\ P(X = maxROI) = 0.25\]
Sample space
All set of possible set of outcomes of an experiment is the sample space.
let's assume, given there are 4 possible directions ($North$, $South$, $East$, $West$).
- Probability of person walking in North Direction is
1/4. Given Sample space ($North$, $South$, $East$, $West$).
\[ P(X = N) = \frac{f}{T} \\ P(X = N) = \frac{P(N)}{P(N)+P(S)+P(E)+P(W)} \\ P(X = N) = \frac{1}{1+1+1+1} \\ P(X = N) = 0.25\]
Sample Space (=4) example
using UnicodePlots;
tblA = (direction=["N","S","E","W"], prob=repeat([1/4], inner=4));
barplot(tblA.direction, tblA.prob,
ylabel="direction", xlabel="probability",
title="sample space=4") sample space=4
┌ ┐
N ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
direction S ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
E ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
W ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
└ ┘
probability - Probability of person walking in $North$ Direction is
1/8. Given Sample space is(N, NE, NW, S, SE, SW, E, W)in Sample Space (=4) example.
\[ P(X = N) = \frac{f}{T} \\ P(X = N) = \frac{P(N)}{P(N)+P(S)+P(E)+P(W)+P(NE)+P(NW)+P(SW)+P(SE)} \\ P(X = N) = \frac{1}{1+1+1+1+1+1+1+1} \\ P(X = N) = \frac{1}{8}\]
Sample Space (=8) example
using UnicodePlots;
tblB = (direction=["N","S","E","W","NE","NW","SE","SW"], prob=repeat([1/8], inner=8));
barplot(tblB.direction, tblB.prob,
ylabel="direction", xlabel="probability",
title="sample space=8") sample space=8
┌ ┐
N ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.125
S ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.125
E ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.125
direction W ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.125
NE ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.125
NW ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.125
SE ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.125
SW ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.125
└ ┘
probability Probability space
Probability Space consists of a triple (Ω, Σ, P), where Ω is a sample space, Σ is a σ-algebra of events, and P is a probability on Σ.
In above example Sample Space (=8) example, Given there are 8 possible outcomes, Probability space = 8, however Sample space can be 4 or 8 depending on probability context.
Cumulative Probability
- Probability of person walking in $North$(ish) Direction is
3/8. Given Sample space is(N, NE, NW, S, SE, SW, E, W).
\[ P(X = N(ish)) = \frac{f}{T} \\ P(X = N(ish)) = \frac{P(N)+P(NE)+P(NW)}{P(N)+P(S)+P(E)+P(W)+P(NE)+P(NW)+P(SW)+P(SE)} \\ P(X = N(ish)) = \frac{1+1+1}{1+1+1+1+1+1+1+1} \\ P(X = N(ish)) = \frac{3}{8}\]
Determining statistical probability accurately depends on context and sample space.
using UnicodePlots;
tblC = (
direction=["N","S","E","W","NE","NW","SE","SW"],
prob=[3/8,1/8,1/8,1/8,3/8,3/8,1/8,1/8]);
barplot(tblC.direction, tblC.prob,
ylabel="direction", xlabel="probability",
title="cumulative probability") cumulative probability
┌ ┐
N ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.375
S ┤■■■■■■■■■■■ 0.125
E ┤■■■■■■■■■■■ 0.125
direction W ┤■■■■■■■■■■■ 0.125
NE ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.375
NW ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.375
SE ┤■■■■■■■■■■■ 0.125
SW ┤■■■■■■■■■■■ 0.125
└ ┘
probability referring back to ROI by Investment group data example
Assuming, one Mutual Fund belongs to only one category ( $A | B | C | D$ ), sample space in this case is 4 because there are only 4 available categories and probability of getting maximum ROI on a given fund is 0.25.
using UnicodePlots;
tbl = (category=["A","B","C","D"], prob=repeat([1/4], inner=4));
barplot(tbl.category, tbl.prob,
ylabel="Category", xlabel="probability",
title="Maximum ROI")barplot(tbl.category, tbl.prob, ylabel="Category", xlabel="probability", title="Maximum ROI"); Maximum ROI
┌ ┐
A ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
Category B ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
C ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
D ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
└ ┘
probability Another example is, if some one wants to know probability of getting at least 4% Maximum ROI. Sample space in this case is still 4, but now since, there are two available categories which can get minimum ROI 4%, which is $Group A=5.6%$ and $Group B=4.3%$. Total probability in this case is 0.50. This probability is also referred as cumulative probability.
using UnicodePlots;
tbl = (category=["A","B","C","D"],
prob=[0.25,0.50,0.50,0.25]);
barplot(tbl.category, tbl.prob,
ylabel="Category", xlabel="probability",
title="Min 4%") Min 4%
┌ ┐
A ┤■■■■■■■■■■■■■■■■■■ 0.25
Category B ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.5
C ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.5
D ┤■■■■■■■■■■■■■■■■■■ 0.25
└ ┘
probability Keep in mind, in above examples, Sample space and possible outcomes are in finite in numbers and hence are considered as discrete probability functions. Later sections, we will see continuous and cumulative probability distributions which often have infinite outcomes.
Dependent and Independent events
Independent events are events that do not affect the outcome of subsequent events.
In cases, when we know that an event has already occurred and if this event alter the probability of another event’s outcome, is referred as Dependent event.
In Finance data analysis, it's very important to understand dependency concepts, because Finance data is tightly integrated and often make huge changes to subsequent events.
For example, A vendor delaying shipment impacts product delivery, directly affecting Revenue and as a result, potential loss is observed.
In ROI by Investment group data example, assuming Group A has no direct or indirect impact on other groups, is considered independent events.
as, this can be seen in this figure and ROI by Investment group data (transposed) table example, Group D ROI is independent of Group A, B & C. While Group A, B & C share few statistical data properties, hence are dependent.
Probability axioms
- The probability of occurrence of any event lies between 0 and 1.
\[P(X) \in (0,1)\]
for example, given there are 4 possible directions ($North$, $South$, $East$, $West$) a person can start walking into, Probability of person walking in any Direction is will always be non-negative and less than one.
\[ 0 <= P(X = N|S|E|W) <= 1\]
similarly, in ROI by Investment group data (transposed) table example, probability of any one stock in Group A, being TSLA is 0.37, AAPL is 0.35 and OTHERS is 0.28.
- The sum of all the probabilities of outcomes should be equal to 1.
\[P(\Omega) = 1\]
similarly, in ROI by Investment group data (transposed) table example, sum of all probabilities equals 1.
- For mutually exclusive events, sum of probabilities is equal to sum of individual event probabilities.
\[P\left(\bigcup _{i=1}^{\infty }E_{i}\right)=\sum _{i=1}^{\infty }P(E_{i}).\]
If a person chose to walk North direction, which is mutually exclusive event than walking in another possible direction like, E, W or S. sum of probabilities is equal to sum of individual event probabilities.
\[ P(X) == 1 == P(X=N) + P(X=S) + P(X=E) + P(X=W)\]
similarly, in ROI by Investment group data (transposed) table example, probability of any one stock in Group A, being TSLA is 0.37, AAPL is 0.35 and OTHERS is 0.28. and sum of all probabilities equals 1.
\[P(X) == 1 == P(X=AAPL) + P(X=TSLA) + P(X=OTHERS) \\ P(X) == 1 == 0.35 + 0.37 + 0.28\]
Probability consequences
Monotonicity
If A is a subset of, or equal to B, then the probability of A is less than, or equal to the probability of B.
\[\quad\text{if}\quad A\subseteq B\quad\text{then}\quad P(A)\leq P(B).\]
The probability of the empty set
\[P(\varnothing)=0.\]
In many cases, $\varnothing$ is not the only event with probability 0.
The complement rule
\[P\left(A^{c}\right) = P(\Omega-A) = 1 - P(A)\]
The numeric bound
It immediately follows from the monotonicity property that
\[0\leq P(E)\leq 1\qquad \forall E\in F.\]
Further consequences
Another important property is:
\[P(A \cup B) = P(A) + P(B) - P(A \cap B)\]
This is called the addition law of probability, or the sum rule. That is, the probability that an event in ''A'' ''or'' ''B'' will happen is the sum of the probability of an event in ''A'' and the probability of an event in ''B'', minus the probability of an event that is in both ''A'' and ''B''.
Addition probability
Marginal probability
- When two events, A and B, are mutually exclusive, the probability that A or B will occur is the sum of the probability of each event.
\[P(A \cup B) = P(A) + P(B)\]
In ROI by Investment group data (transposed) table example, probability of any stock in Group A, being TSLA or AAPL is sum of probability being TSLA and probability being AAPL.
\[P(X == TSLA|AAPL) = P(X==TSLA) + P(X==AAPL) \\ P(X == TSLA|AAPL) = 0.37 + 0.35 \\ P(X == TSLA|AAPL) = 0.72 \\\]
Joint probability
- When two events, A and B, are non-mutually exclusive, the probability that A or B will occur is:
\[P(A \cup B) = P(A) + P(B) - P(A \cap B)\]
In ROI by Investment group data (transposed) table example, what is ths probability of a Stock is TSLA, and belongs to Group A
\[P(X == TSLA \cap A) = P(X==TSLA) + P(X==A) - P(X==TSLA \cap X==A) \\ P(X == TSLA) = \frac{59}{35+59+48+36+80+42+25+25+25+25} \\ P(X == TSLA) = \frac{59}{400} \\ P(X == TSLA) = 0.1475 \\ P(X == A) = \frac{35+37+28}{35+59+48+36+80+42+25+25+25+25} \\ P(X == A) = \frac{100}{400} \\ P(X == A) = 0.25 \\ P(X==TSLA \cap X==A) = \frac{37}{400} \\ P(X==TSLA \cap X==A) = 0.0925 \\ P(X == TSLA \cap A) = P(X==TSLA) + P(X==A) - P(X==TSLA \cap X==A) \\ P(X == TSLA \cap A) = 0.1475 + 0.25 - 0.0925 \\ P(X == TSLA \cap A) = 0.3050 \\\]
Conditional probability
In general, conditional probability measures the probability of an outcome B provided we know that another outcome A has already occurred. The formula for conditional probability is $P(B|A)$ read as "Probability of Event B $P(B)$ given $P(A)$.
for example, delayed shipment directly impacts product delivery.
- If A and B are the outcomes of dependent events, then
\[P(A \cap B) = P(A).P(B|A) \\ P(B|A) = \frac{P(A \cap B)}{P(A)}\]
In ROI by Investment group data (transposed) table example, Given a Stock is NIKE, what is the probability that it belongs to Group C
\[P(X==C | X==NIKE) = \frac{P(X==C \cap X==NIKE)}{P(X==NIKE)} \\ P(X==C | X==NIKE) = \frac{\frac{38}{400}}{\frac{80}{400}} \\ P(X==C | X==NIKE) = \frac{38}{80} \\ P(X==C | X==NIKE) = 0.475 \\\]
- and thus If A and B are the outcomes of independent events, then
\[P(B|A) = P(B) \\ P(A \cap B) = P(A).P(B)\]
In ROI by Investment group data (transposed) table example, Given There are only 4 MF group in dataset, what is the probability a stock is from Group C and is MSFT
\[P(X==C | X==MSFT) = P(X==C).P(X==MSFT) \\ P(X==C | X==MSFT) = 0.25 * \frac{42}{400} \\ P(X==C | X==MSFT) = 0.25 * 0.125 \\ P(X==C | X==MSFT) = 0.02625 \\\]
Bayes Theorem
as per wikipedia: In probability theory and statistics, Bayes' theorem, describes the probability of an event, based on prior knowledge of conditions that might be related to the event.
\[P(A | B) = \frac{P(B | A) * P(A)}{P(B)}\]
- where A and B are events and
\[{\displaystyle P(B)\neq 0}.\]
- $P(A\mid B)$ is a conditional probability: the probability of
event Aoccurring given thatBis true. It is also called the posterior probability of A given B. - $P(B\mid A)$ is also a conditional probability: the probability of
event Boccurring given thatAis true. It can also be interpreted as the likelihood of A given a fixed B because
\[{\displaystyle P(B\mid A)=L(A\mid B)}.\]
P(A)andP(B)are the probabilities of observingAandBrespectively without any given conditions; they are known as the prior probability and marginal probability.
Bayes theorem is a book on it's own and this example just scratches the surface.
Bayes theorem is very useful in calculating probabilities of events when other probabilities are known.
In ROI by Investment group data (transposed) table example, Given a Stock is NIKE, what is the probability that it belongs to Group C
\[P(X==C | X==NIKE) = \frac{P(X==C \cap X==NIKE)}{P(X==NIKE)} \\ P(X==C | X==NIKE) = \frac{\frac{38}{400}}{\frac{80}{400}} \\ P(X==C | X==NIKE) = \frac{38}{80} \\ P(X==C | X==NIKE) = 0.475 \\\]
Permutations and Combinations
Permutation and Combination are the ways to write a group of objects by selecting them in a specific order and forming their subsets. To arrange groups of data in a specific order permutation and combination formulas are used. Selecting the data or objects from a certain group is said to be permutations, whereas the order in which they are arranged is called combination. Permutation and Combination formulas are very useful in solving various problems in mathematics.
Combinations
Selecting a part of items from a collection of distinct members, when order is not important, is often referred as Combinations.
Combinations without repetition
\[C(n,r) = nCr = _{n}C^{r} =_{n}C_{r} = \left(\frac{n}{r}\right) = \frac{n!}{r!(n−r)!}\]
- where n is the number of things to choose from
- r is number of chosen things
- no repetition
- order doesn't matter in Combinations
In ROI by Investment group data (transposed) table example, Given There are 3 Stocks in Group A. AAPL,TSLA and OTH. What are different combinations of taking 2 stocks at a time, given repetition is not allowed.
\[_{n}C_{r} = \frac{n!}{r!(n−r)!} \\ \\ _{3}C_{2} = \frac{3!}{2!(3−2)!} \\ \\ _{3}C_{2} = \frac{3*2*1}{2*1*(1)} \\ \\ _{3}C_{2} =_{3}C_{2} = 3\]
We can intuitively test this, Given AAPL, TSLA and OTH, there only 3 combinations of two stocks.
- AAPL, TSLA
- TSLA, OTH
- AAPL, OTH
In ROI by Investment group data (transposed) table example, Given There are total 10 Stocks in all Groups.. What are different combinations of taking 2 stocks at a time, given repetition is not allowed.
\[_{n}C_{r} = \frac{n!}{r!(n−r)!} \\ \\ _{10}C_{2} = \frac{10!}{2!(10−2)!} \\ \\ _{10}C_{2} = \frac{10*9*8!}{2*1*(10-2)!} \\ \\ _{10}C_{2} = \frac{10*9*8!}{2*1*(8)!} \\ \\ _{10}C_{2} = \frac{10*9}{2*1} \\ \\ _{10}C_{2} = 45\]
Combinations with repetition
\[_{n}C_{r} = \frac{(r + n - 1)!}{r!(n−1)!}\]
- where n is the number of things to choose from
- r is number of chosen things
- repetition is allowed
- order doesn't matter in Combinations
In ROI by Investment group data (transposed) table example, Given There are 3 Stocks in Group A. AAPL,TSLA and OTH. What are different combinations of taking 2 stocks at a time, given repetition is allowed.
\[_{n}C_{r} = \frac{(r + n - 1)!}{r!(n−1)!} \\ \\ _{3}C_{2} = \frac{(3 + 2 - 1)!}{2!(3−1)!} \\ \\ _{3}C_{2} = \frac{4!}{2!*(2)!} \\ \\ _{3}C_{2} = \frac{4*3*2*1}{2*1*2*1} \\ \\ _{3}C_{2} = 6\]
We can intuitively test this, Given AAPL, TSLA and OTH, there only 6 combinations of two stocks.
- AAPL, TSLA
- TSLA, OTH
- AAPL, OTH
- AAPL, AAPL
- TSLA, TSLA
- OTH, OTH
In ROI by Investment group data (transposed) table example, Given There are total 10 Stocks in all Groups.. What are different combinations of taking 2 stocks at a time, given repetition is allowed.
\[_{n}C_{r} = \frac{(r + n - 1)!}{r!(n−1)!} \\ \\ _{10}C_{2} = \frac{(10 + 2 - 1)!}{2!(10−1)!} \\ \\ _{10}C_{2} = \frac{11!}{2!*(9)!} \\ \\ _{10}C_{2} = \frac{11*10*9!}{2*1*9!} \\ \\ _{10}C_{2} = \frac{11*10}{2*1} \\ \\ _{3}C_{2} = 55\]
Permutations
Selecting a part of items in ordered form, from a collection of distinct members is often referred as Permutations.
A Permutation is an ordered Combination.
Permutation without repetition
\[P(n,r) = nPr = _{n}P^{r} =_{n}P_{r} = \frac{n!}{(n−r)!}\]
- where n is the number of things to choose from
- r is number of chosen things
- repetition is not allowed
- order does matter in Permutations
In ROI by Investment group data (transposed) table example, Given There are 3 Stocks in Group A. AAPL,TSLA and OTH. What are different Permutations of taking 2 stocks at a time, given repetition is not allowed.
\[_{n}P_{r} = \frac{n!}{(n−r)!} \\ \\ _{3}P_{2} = \frac{3!}{(3−2)!} \\ \\ _{3}P_{2} = 3*2*1 \\ \\ _{3}P_{2} = 6\]
In ROI by Investment group data (transposed) table example, Given There are total 10 Stocks in all Groups.. What are different Permutations of taking 2 stocks at a time, given repetition is not allowed.
\[_{n}P_{r} = \frac{n!}{(n−r)!} \\ \\ _{10}P_{2} = \frac{10!}{(10−2)!} \\ \\ _{10}P_{2} = \frac{10*9*8!}{(8!} \\ \\ _{10}P_{2} = 10*9 \\ \\ _{10}P_{2} = 90\]
Permutation with repetition
\[_{n}P_{r} = n^r\]
- where n is the number of things to choose from
- r is number of chosen things
- repetition is allowed
- order does matter in Permutations
In ROI by Investment group data (transposed) table example, Given There are 3 Stocks in Group A. AAPL,TSLA and OTH. What are different Permutations of taking 2 stocks at a time, given repetition is allowed.
\[_{n}P_{r} = n^r \\ \\ _{3}P_{2} = 3^2 \\ \\ _{3}P_{2} = 9\]
In ROI by Investment group data (transposed) table example, Given There are total 10 Stocks in all Groups.. What are different Permutations of taking 2 stocks at a time, given repetition is allowed.
\[_{n}P_{r} = n^r \\ \\ _{10}P_{2} = 10^2 \\ \\ _{10}P_{2} = 100\]
Probability Distributions Functions (PDFs)
Probability Distribution functions (referred as PDFs), not to be confused with Probability density function (PDF), is the mathematical function that gives the probabilities of occurrence of different possible outcomes for an experiment. It is a mathematical description of a random phenomenon in terms of its sample space and the probabilities of events (subsets of the sample space).
\[ PDFs \Rrightarrow \left[\begin{array}{c} Discrete \Leftrightarrow PMF \\ Continuous \Leftrightarrow PDF \end{array}\right] \Rrightarrow CDF \left[\begin{array}{c} Discrete \Leftrightarrow CDF \\ Continuous \Leftrightarrow CDF \end{array}\right]\]
In ROI by Investment group data (transposed) table example, Given Group A observe highest ROI, what is the probability that TSLA is driving most of the ROI. This particular problem can be very hard to solve mathematically using probability theorems, however it's very obvious and intuitive.
Probability distribution functions help visualize and analyze data statistically in such scenarios.
just to keep reader and objective of this tutorials aligned, the whole reason, we are learning about probability distributions is, it helps us visualize data in terms of "central or distributed" tendency and/or estimating an event or point of interest in terms of maximum likelihood of occurrence.
Probability Mass Function (PMF)
A probability mass function tells us the probability that a discrete random variable takes on a certain value.
let's assume, given there are 4 possible directions a person can start walking ($North$, $South$, $East$, $West$).
- Probability of person walking in North Direction is
1/4. Given Sample space ($North$, $South$, $East$, $West$).
\[ P(X = N) = \frac{f}{T} \\ P(X = N) = \frac{P(N)}{P(N)+P(S)+P(E)+P(W)} \\ P(X = N) = \frac{1}{1+1+1+1} \\ P(X = N) = 0.25\]
PMF Distributions
using UnicodePlots;
tblA = (direction=["N","S","E","W"], prob=repeat([1/4], inner=4));
barplot(tblA.direction, tblA.prob, ylabel="direction",
xlabel="PMF", title="sample space=4") sample space=4
┌ ┐
N ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
direction S ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
E ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
W ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
└ ┘
PMF Properties of PMF
We already discussed these in Probability axioms section.
- The probability of occurrence of any event lies between 0 and 1.
\[P(X) \in (0,1)\]
- The sum of all the probabilities of outcomes should be equal to 1.
\[P(\Omega) = 1\]
- For mutually exclusive events, sum of probabilities is equal to sum of individual event probabilities.
\[P\left(\bigcup _{i=1}^{\infty }E_{i}\right)=\sum _{i=1}^{\infty }P(E_{i}).\]
\[ P(X) == 1 == P(X=A) + P(X=B) + P(X=C) + P(X=D)\]
The two most common examples of discrete variables probability mass functions in practice are for the Bernoulli Distributions, Binomial Distributions and the Poisson Distributions.
These are discussed in Statistical Distributions section.
referring back to ROI by Investment group data example
Assuming, one Mutual Fund belongs to only one category ( $A | B | C | D$ ), sample space in this case is 4 because there are only 4 available categories and probability of getting maximum ROI on a given fund is 0.25. Below plot shows Probability mass distributions of discrete variables.
using UnicodePlots;
tbl = (category=["A","B","C","D"],
prob=repeat([1/4], inner=4));
barplot(tbl.category, tbl.prob, ylabel="Category",
xlabel="probability", title="Maximum ROI") Maximum ROI
┌ ┐
A ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
Category B ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
C ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
D ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.25
└ ┘
probability Probability Density Function (PDF)
Similar to PMF(probability mass function), PDF - Probability density functions tells us the probability that a continuous random variable takes on a certain value. Now since continuos random variable can take any of the value in an infinite data set, it's represented as bell curve as density function in a plot. and any point under the curve represent probability assigned to Random variable.
PDF have similar Probability axioms.
- The probability of occurrence of any event lies between 0 and 1.
\[P(X) \in (0,1)\]
- The sum of all the probabilities of outcomes should be equal to 1.
Sum of all the probabilities of outcomes is calculated as area under the curve.
\[P(\Omega) = 1\]
- Because continuous variables represent an infinite set of data under the curve, probability of one event is represent as $one point in AUC (area under curve)$, which is $0$.
\[P(\varnothing)=0.\]
The most common and widely used example of continuous variables probability density functions in practice is Normal Gaussian Distributions.
using UnicodePlots; # hide
histogram(randn(100_000) .* .1, nbins=40, vertical=true, height=10) ┌ ┐
19 319 ⠀⠀⠀⠀⠀⠀⠀⠀⠀█▇⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀██⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀▅██▆⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀████⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀████⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀▆████▆⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀██████⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀▂██████▂⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀████████⠀⠀⠀⠀⠀
0 ⠀⠀⠀▁▂▇████████▇▂⠀⠀⠀
└ ┘
⠀-0.5⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀0.45⠀
⠀⠀μ ± σ: -0.0 ± 0.1⠀⠀ Cumulative Density Function (CDF)
CDF for Discrete variables
Another example is, if some one wants to know probability of getting at least 4% Maximum ROI. Sample space in this case is still 4, but now since, there are two available categories which can get minimum ROI 4%, which is $Group A=5.6%$ and $Group B=4.3%$. Total probability in this case is 0.50. This probability is also referred as cumulative probability.
Below plot shows cumulative mass distributions of discrete variables.
using UnicodePlots;
tbl = (category=["A","B","C","D"], prob=[0.25,0.50,0.50,0.25]);
barplot(tbl.category, tbl.prob,
ylabel="Category", xlabel="probability", title="Min 4%") Min 4%
┌ ┐
A ┤■■■■■■■■■■■■■■■■■■ 0.25
Category B ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.5
C ┤■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.5
D ┤■■■■■■■■■■■■■■■■■■ 0.25
└ ┘
probability CDF for Continuous variables
using UnicodePlots;
x = 0:0.1:1;
lineplot(x, sin.(x), title="CDF for Continuous variables", name ="S Curve") ⠀⠀⠀⠀⠀⠀⠀CDF for Continuous variables⠀⠀⠀⠀⠀⠀⠀
┌────────────────────────────────────────┐
0.9 │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀│ S Curve
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣀⠤⠒⠉│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⡠⠒⠉⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣀⠤⠊⠁⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣀⠔⠊⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣀⠔⠊⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⠔⠊⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⡠⠊⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡠⠔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⠔⠊⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡠⠒⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⢀⠔⠊⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⡠⠔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⢀⡠⠊⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
0 │⣀⠔⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
└────────────────────────────────────────┘
⠀0⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀1⠀ PDF - CDF Relation
\[ PDFs \Rrightarrow \left[\begin{array}{c} Discrete \Leftrightarrow PMF \\ Continuous \Leftrightarrow PDF \end{array}\right] \Rrightarrow CDF \left[\begin{array}{c} Discrete \Leftrightarrow CDF \\ Continuous \Leftrightarrow CDF \end{array}\right]\]
Below figure is the most important takeaway lesson in this tutorial. This figure shows, how simple differential calculus and integral calculus relates PDF to CDFs.
Understanding this relationship forms the basis of using calculus to use differentiation based techniques to predict statistical associations and data pattern.
using CairoMakie, Distributions; # hide
dMF = Dict("A" => 5.6, "B" => 4.3, "C" => 3.3, "D" => 0.3)
dMFProb = Dict("A" => 0.25, "B" => 0.25, "C" => 0.25, "D" => 0.25)
dMFPCProb = Dict("A" => 1.0, "B" => 0.75, "C" => 0.50, "D" => 0.25)
x = 1:4
kPDF = Array{String, 1}()
vPDF = Array{Float64, 1}()
kCDF = Array{String, 1}()
vCDF = Array{Float64, 1}()
# for PDf
N = 100_000; # samples
r1 = rand(Uniform(0.3, 5.6), N) # range
w1 = pdf.(Normal(), r1) # weighted samples
r2 = rand(Uniform(0, 1.0), N) # range
w2 = pdf.(Normal(), r2) # weighted samples
for i in keys(dMFProb)
sort!(push!(kPDF, i), rev = true)
sort!(push!(vPDF, get(dMFProb, i, 0)), rev = true)
end
for i in keys(dMFPCProb)
sort!(push!(kCDF, i), rev = true)
sort!(push!(vCDF, get(dMFPCProb, i, 0)))
end
fig = Figure(backgroundcolor=:white, resolution=(600,600), title="sds")
ax11 = Axis(fig[1,1],
title=L"PMF \frac{P(A)=P(B)=P(C)=P(D)=0.25}{P(ROI)=0.3|3.3|4.3|5.6}",
titlecolor="gray50",
(xticks = (1:4, kPDF)), limits = (0, 5, 0, 1.1)); # hide
CairoMakie.barplot!(x, vPDF, bar_labels=:y, color=x,
label_size=14, label_rotation=pi/3, label_offset=-20, label_color=:white);
ax12 = Axis(fig[1,2],
title=L"CDF \frac{P(0.3)+P(3.3)+P(4.3)}{P(ROI>=4.3)}",
titlecolor=:gray50,
(xticks = (1:4, kCDF)), limits = (0, 5, 0, 1.1)); # hide
CairoMakie.barplot!(ax12, 1:4, vCDF, bar_labels=:y, color=x,
label_size=14, label_rotation=pi/3, label_offset=-20,label_color=:white);
ax21 = Axis(fig[2,1],
title=L"\frac{PDF=f(x)}{ f(x)=\frac {d(F(x))} {dx} }",
titlecolor="gray50");
CairoMakie.density!(ax21, r1, weights = w1)
ax22 = Axis(fig[2,2], title=L"\frac{CDF=F(x)}{ F(x)=\int_{-\infty} ^1f(x)dx }",
titlecolor=:gray50);
ecdfplot!(ax22, randn(200))
fig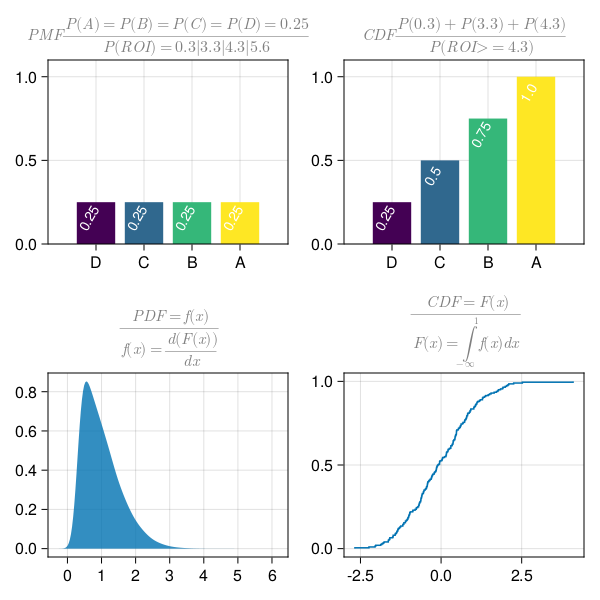
Calculating Probability Distributions on Finance data
probability distributions helps us visualize data in terms of "central or distributed" tendency and/or estimating an event or point of interest in terms of maximum likelihood of occurrence. These statistical distribution "Area under curve" represent probabilities of likelihood of an event occurring, which is what, eventually drive predictions in Machine learning.